Devin Fusion: Frontier Performance at 35% Lower Cost
Engineering teams are lighting money on fire.
It's no longer sustainable to use the most expensive models on every task. But existing tools for mixing models suck. They look nice on most benchmarks but fail to write code you'd actually merge.
At Cognition, we specialize in routing across frontier models without sacrificing intelligence. Today, we're sharing our work on a new kind of multi-model harness, Devin Fusion, that is substantially better at mixing models while reducing costs and maintaining intelligence on real-world usage. We found it maintains frontier and Fable 5-level performance at 35% lower cost on FrontierCode, a new state-of-the-art coding benchmark that measures both code correctness and quality.
Devin Fusion: Frontier Performance at 35% Lower Cost
Score on FrontierCode Extended Benchmark and average cost per task
In the rest of this post, we break down why good model routing is so hard, and the two techniques that make it all work: the "sidekick" approach and dynamic mid-session routing.
We welcome you to try Devin Fusion in preview at app.devin.ai/signup.
The Trick: Sidekick
The key idea behind our architecture is to run two parallel agents: one with a frontier model, the other with a more cost-effective "sidekick" model. Both are fully capable agents with their own toolsets and ability to gather & act on their own context.
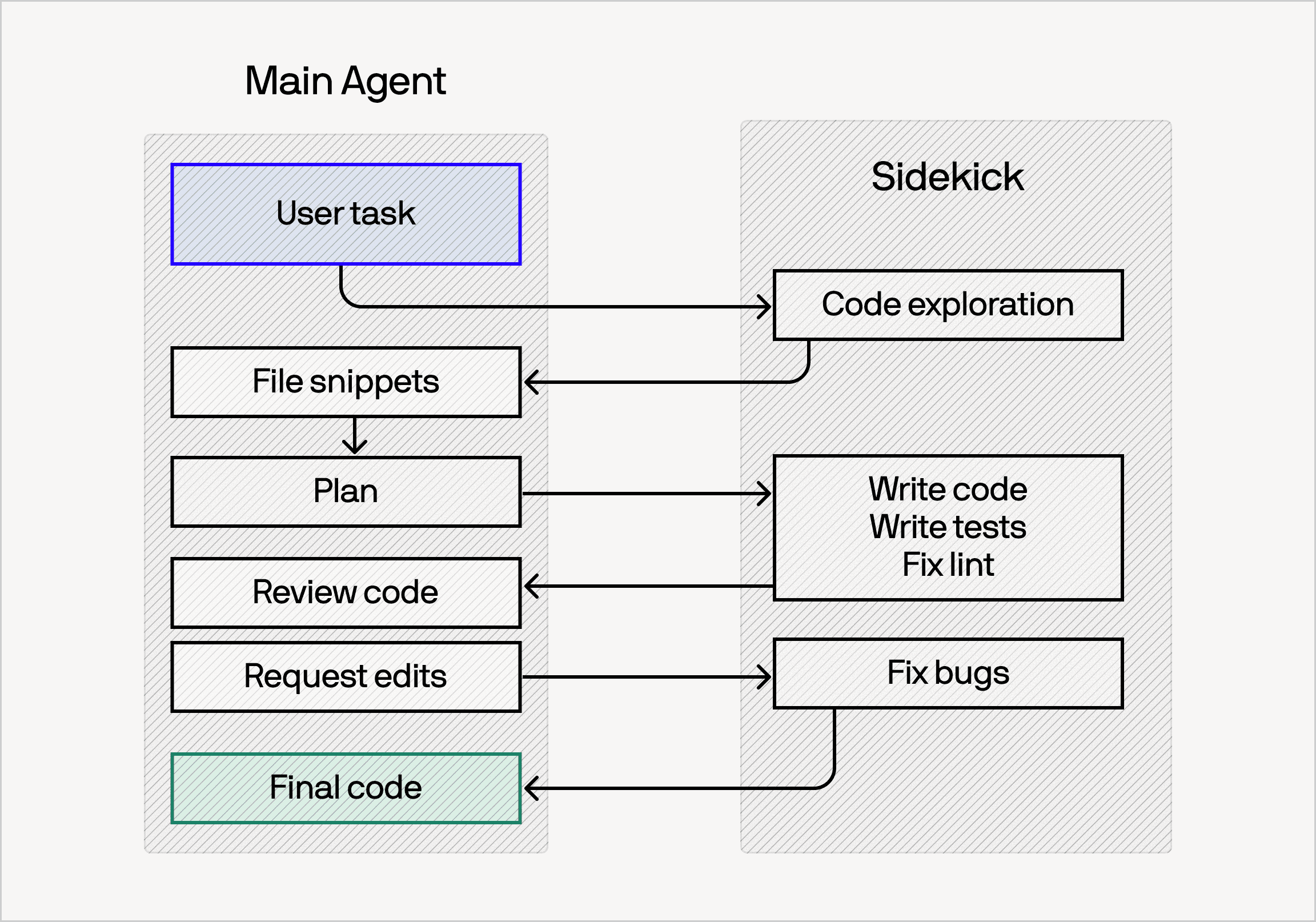
As the task progresses, the main agent decides which tasks to give the sidekick and which tasks to do itself. Making sidekick work well in practice, however, requires deeply tuning the interaction patterns. We've found that the main agent should take minimal actions, and only read what is absolutely necessary. By default it should delegate and monitor, while making the significant decisions: the plan, the interpretation of ambiguity, the final review.
This approach fixes the primary problems with more basic model routing:
- It retains real frontier intelligence rather than "benchmark-score" intelligence. Routers often over-fit to specific benchmarks. By keeping a frontier model in the mix, the sidekick approach continues to benefit from frontier model creativity and general intelligence.
- It generalizes beyond single-prompt tasks and question-answering. Model routers often route to a single model for the entire task. Prompts often do not contain enough information about the task to properly discern difficulty. Moreover, the user might have difficult followups to simple initial prompts. Being able to move between the smart model and sidekick dynamically makes this system much more robust.
- It avoids costly cache misses when routing between models. We've previously explored a "Smart Friend" tool, and Anthropic released a similar "Advisor" tool. The core of both these ideas is to give one model a tool to query another model for helpful advice. The catch? Upon every call to the other model, the context for the task is not shared in a way that is cached, and you pay a very expensive price. In the sidekick setup, both the main model and sidekick model maintain their own persistent, cached contexts.
Of course, there are many implementation details we had to overcome to achieve the capabilities of Devin Fusion. For example, most cached inputs only have a 5-minute expiry. We encourage the reader to think about how to engineer around this. We'd love to trade notes!
Sidekick scales better as models get smarter
Recent models, and Fable 5 especially, perform unusually well in these multi-agent setups. Fable delegates work more intelligently, requests context more efficiently, and plans more precisely, all of which yield a larger cost improvement with minimal impact on intelligence. This suggests that the sidekick pattern is one that will become more useful as base models get better.
In our testing, Fusion with Fable 5 is 41% cheaper than a pure Fable 5 harness, versus 35% with Opus and GPT-5.5-level models. That gap may look modest, but we believe it understates the real difference. The non-Fable numbers reflect many rounds of tuning of the Devin Fusion harness; the Fable 5 numbers don't, since access was cut off before we could apply them.*
Examples of Sidekick in Action
To better understand how the sidekick works, we inspected how using sidekick impacts cost and performance on a representative sample of FrontierCode tasks. Here we present both good and bad examples of sidekick usage.
Dynamic Mid-Session Routing
With sidekick in your arsenal, you must still make sure to choose the right models for the task. We decide on different models for the main agent or sidekick depending on task type and complexity. It can be dangerous, however, to choose a model at the start and then realize later on that a different one would be better suited. Similarly, you might also want to move the task from the sidekick back to the main agent if it is proving too challenging. To handle these cases, we use lightweight classifiers during task execution to signal when we need to switch to the main agent or use a different model entirely.
We would like to be cache-efficient when switching between models, and doing so requires some artful engineering. We accomplish this by switching the model during context compaction, which would trigger a cache miss anyway. Each time we trigger compaction, we take it as an opportunity to evaluate the situation and switch the model that's in charge, effectively getting model switching “for free”. Note that this means we can even “upgrade” our sidekick model without going back to the main model, at no extra cache penalty.
To illustrate, we chose a task from our internal development that used Devin Fusion.
Edit the service to use a non-atomic Valkey batch and batch delete API, then open a PR
Results
We benchmarked our new harness with and without the ability to use Fable 5*, and found exciting improvements with both configurations.
Without including Fable 5, our Devin Fusion multi-model harness gives a 35% cost improvement on FrontierCode relative to frontier models like GPT-5.5 and Opus 4.8, while maintaining performance matching the frontier.
Fable 5 proved to be exceptionally performant in this multi-model harness, achieving a 41% cost reduction, while maintaining the same performance as Fable 5 in a traditional agent harness. While Fable is currently not a generally available model, we are excited to extend Fable to users of Devin Fusion once access is restored.
FrontierCode ExtendedScore vs Cost
* On June 12, 2026, access to Fable 5 was suspended in accordance with a US government directive (anthropic.com/news/fable-mythos-access). As of this blogpost, access has not been restored. Results with Fable 5 are reported based on measurements from before this suspension and on the internal version of Devin Fusion at the time.
The Sanity Check
We set out to build a harness that not only performs well on benchmarks, but actually feels good in real use. We enabled Fusion for a set of users internally at Cognition, and we found that 88% of their merged PRs were driven entirely by the automated Fusion router.
Of course, our end desire is to test this harness on a much wider set of tasks than what our internal usage covers. That's why we're very excited to release a preview of Devin Fusion to users in our cloud agent.
The rising importance of hybrid-model harnesses
The age of using one model for all of your work is coming to an end. The rising costs of frontier intelligence are reaching prohibitive levels in engineering organizations small and large. Moreover, there is now a growing range of model options at different price and intelligence levels, and with the right prompting, many of the sub-frontier models are fully capable of doing most engineering work. You wouldn't drive a Lamborghini to the grocery store, so why should you take a model that can discover zero-day vulnerabilities in software and use it to round the corner of a button?
Moreover, using a multi-model harness allows you to capture the relative strengths of various frontier models. For example, at Cognition, we find some models to be particularly good at UI testing, and different models to be good at identifying complicated bugs in PRs. There is also a growing set of capable open-source models. This makes it easier to train specialized intelligence on specific domains. And as models emerge that excel at particular languages, tasks, or libraries, investing in multi-model capabilities only becomes more important.
We share the techniques we use here, because it will only become more important for agent builders to harness the growing diversity of intelligent models. We're just getting started, and Devin Fusion is just one of many steps on this journey.
We'd love for you to put it to work on real tasks and tell us where it breaks. Try it at app.devin.ai/signup, and if you find our work interesting, consider working with us!